Daniel Janus’s blog
Making of “Clojure as a dependency”
In my previous post, “Clojure as a dependency”, I’ve presented the results of some toy research on Clojure version numbers seen in the wild. I’m a big believer in reproducible research, so I’m making available a Git repo that contains code you can run yourself to reproduce these results. This post is an experience report from writing that code.
There are two main components to this project: acquisition and analysis of data (implemented in the namespaces versions.scrape and versions.analyze, respectively). Let’s look at each of these in turn.
Data acquisition
This step uses the GitHub API v3 to:
- retrieve the 1000 most popular Clojure repositories (using the Search repositories endpoint and going through all pages of the paginated result);
- for each of these repositories, look at its file list (in the master branch) and pick up any files named
project.cljordeps.ednin the root directory, using the Contents endpoint); - parse each of these files and extract the list of dependencies.
As hinted by the namespace, I’ve opted to use Skyscraper to orchestrate the process. It would arguably have been simpler to use GitHub’s GraphQL v4 API, but I wanted to showcase Skyscraper’s custom parsing facilities.
There’s no actual HTML scraping going on (all processors use either JSON or Clojure parsers), but Skyscraper is still able to “restructure” the result – traverse the graph endpoint in a manner similar to that of GraphQL – with very little effort. It would have been possible with any other RESTful API. Plus, we get goodies like caching or tree pruning for free.
Most of the code is straightforward, but parsing of project.clj merits some explanation. Some of my initial assumptions proved incorrect, and it’s fun to see how. I initially tried to use clojure.edn, but Leiningen project definitions are not actually EDN – they are Clojure code, which is a superset of EDN. So I had to resort to read-string from core – with *read-eval* bound to nil (otherwise the code would have a Clojure injection vulnerability – think Bobby Tables). Needless to say, some project.cljs turned out to depend on read-eval.
Some projects (I’m looking at you, Closh, Babashka and sci) keep the version number outside of project.clj, in a text file (typically in resources/), and slurp it back into project.clj with a read-eval’d expression:
(defproject closh-sci
#=(clojure.string/trim
#=(slurp "resources/CLOSH_VERSION"))
…)
A trick employed by one project, Metabase, is to dynamically generate JVM options containing a port number at parse time, so that test suites running at the same time don’t clash with each other:
#=(eval (format "-Dmb.jetty.port=%d" (+ 3001 (rand-int 500))))
Finally, it turned out that defproject is not always a first form in project.clj. Some projects, like bridge, only contain a placeholder project.clj with no forms; others, like aleph, first define some constants, and then refer to them in a defproject form. If those constants contain parts of the dependencies list, then those dependencies won’t be processed correctly. Fortunately, not a lot of projects do this, so it doesn’t skew the results much.
Anyway, the end result of the acquisition phase is a sequence of maps describing project definitions. They look like this:
{:name "clojure-koans",
:full-name "functional-koans/clojure-koans",
:deps-type :leiningen,
:page 1,
:deps {org.clojure/clojure #:mvn{:version "1.10.0"},
koan-engine #:mvn{:version "0.2.5"}}},
:profile-deps {:dev {lein-koan #:mvn{:version "0.1.5"}}}
Homogeneity is important: every dependency description has been converted to the cli-tools format, even if it comes from a project.clj.
Data analysis
I’ve long been searching for a way to do exploratory programming in Clojure without turning the code to a tangled mess, portable only along with my computer.
Exploratory (or research) programming is very different from “normal” programming. In the latter, most of the time you typically focus on a coherent project – a program or a library. In contrast, in the former, you spend a lot of time in the REPL, trying all sorts of different things and defing new values derived from already computed ones.
This is very convenient, but it’s extremely easy to get carried away in the REPL and get lost in a sea of defs. If you want to redo your computations from scratch, just about your only option is to take your REPL transcript and re-evaluate the expressions one by one, in the correct order. Cleaning up the code (e.g. deglobalizing) as you go is very difficult.
I’ve found an answer: Plumatic Graph, part of the plumbing library. There are a plethora of uses for it: for example, at Fy, my current workplace, we’re using it to define our test fixtures. But as it turns out, it makes exploratory programming enjoyable.
The bulk of code in versions.analyze consists of a big definition of a graph, with nodes representing computations – things that I’d normally have def’d in a REPL. Consequently, most of these definitions are short and to the point. I also gave the nodes verbose, descriptive, explicit names. Name and conquer. raw-repos is the output from data acquisition, repos is an all-important node containing those raw-repos that were successfully parsed, and most other things depend on it.
It also doesn’t obstruct much the normal REPL research flow. My normal workflow with REPL and Graph is something along the lines of:
(def result (main))- evaluate something using inputs from
result - nah, it leads nowhere
- evaluate something else
- hey, that’s interesting!
- add a new node to the graph definition
- GOTO 1
Thanks to Graph’s lazy compiler, I can re-evaluate anything at need and have it evaluate only the things needed, and nothing else. Also, because the graph is explicit, it’s fairly easy to visualize it. (Click the image to open it in full-size in another tab.)
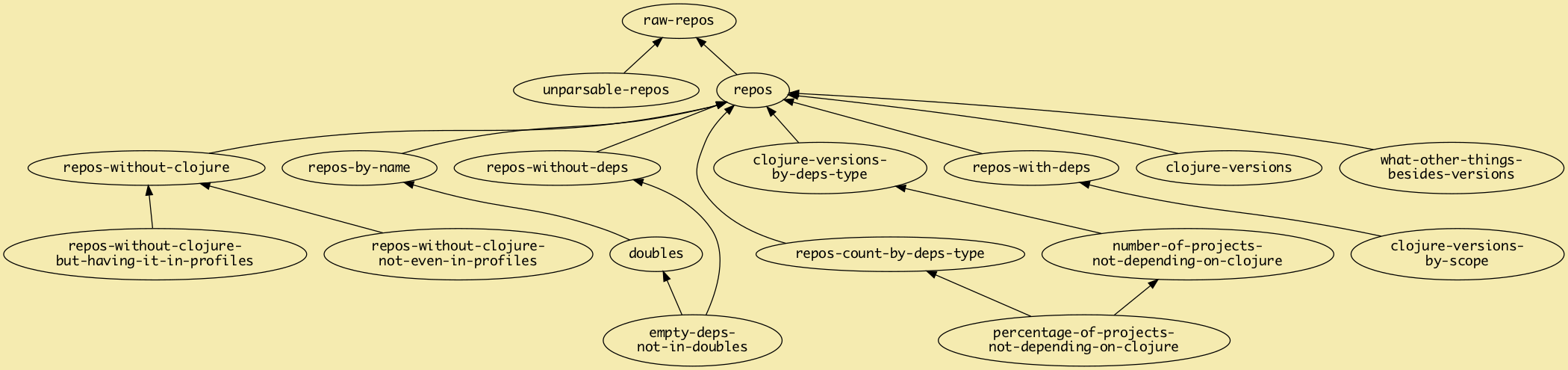
Because it’s lazy, it doesn’t hurt to put extra things in there just in case, even when you’re not going to report them. For example, I was curious what things besides a version number people put in dependencies. :exclusions, for sure, but what else? This is the :what-other-things-besides-versions node.
Imagine my surprise when I found :exlusions (sic) in there, which turned out to be a typo in shadow-cljs’ project.clj! I submitted a PR, and Thomas Heller merged it a few days after.
My only gripe with Graph is that it runs somewhat contrary to the current trends in the Clojure community: for example, it doesn’t support namespaced keywords (although there’s an open ticket for that). But on the whole, I’m sold. I’ll definitely be using it in the next piece of research in Clojure, and I’m on a lookout for something similar in pure R. If you know something, do tell me!
Some words on plotting
The plot from previous post has been generated in pure R, using ggplot2 (an extremely versatile API). Clojure generates a CSV with munged data, and then R reads that CSV as a data frame and generates the plot in a few lines.
I’ve briefly played around with clojisr, a bridge between Clojure and R. It was an enlightening experiment, and it would let me avoid the intermediate CSV, but I decided to ditch it for a few reasons:
- It pulls in quite a few dependencies (I wanted to keep them down to a minimum), and requires some previous setup on the R side.
- I’d much rather write my R as R, since I’m comfortable with it, rather than spend time wondering how it maps to Clojure. This is similar to the SQL story: these days I prefer HugSQL over Korma, unless I have good reasons to choose otherwise.
- clojisr opens up a child R process just by
requireing a namespace. I’m not a fan of that.
But it’s definitely very promising! I applaud the effort and I’ll keep a close eye on it.
Key takeaways
- Skyscraper makes data acquisition bearable, if not fun.
- Plumatic Graph makes writing research code in Clojure fun.
- ggplot makes plotting data fun.
- Clojure makes programming fun. (But you knew that already.)