Daniel Janus’s blog
Things I wish Git had: Commit groups
1 July 2021
Intro
Everyone 1 and their dog 2 loves Git. I know I do. It works, it’s efficient, it has a brilliant data model, and it sports every feature under the sun. In 13 years of using it, I’ve never found myself needing a feature it didn’t have. Until recently.
But before I tell you about it, let’s talk about GitHub.
There are three groups of GitHub users, distinguished by how they prefer to merge pull requests:
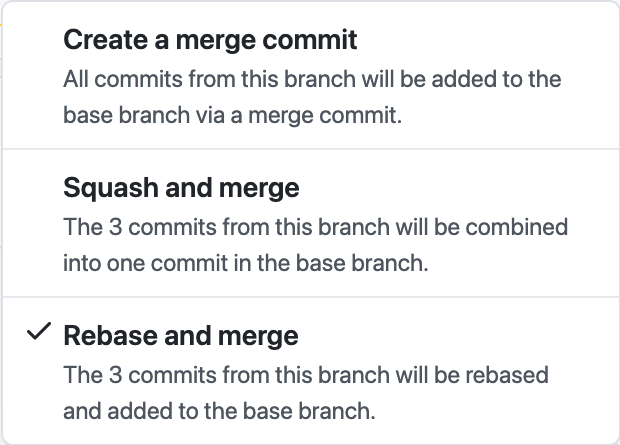
Merge commit, squash, or rebase? There’s no single best answer to that question. A number of factors are at play in choosing the merge strategy: the type of the project, the size, workflow and preferences of the team, business considerations, and so on. You probably have your own preference if you’ve used GitHub to collaborate with a team.
I’ll talk for a while about the pros and cons of each approach. But first, let’s establish a setting. Imagine that your project has a main branch, from which a feature branch was created off at one point. Since then, both branches have seen developments, and now after feature has undergone reviews and testing, it’s ready to be merged back to main:

Create a merge commit
Merge commits are the original answer that Git has to combining changes. A merge commit has two or more parents and brings in all the changes from them and their ancestors:

In this example, Git has created a new commit, number 9, that merges commits 6 and 8. The branch main now points to that new commit, and so contains all changes in the range 1–8.
Merge commits are extremely versatile and scale well, especially for complicated workflows with multiple maintainers, each responsible for different part of the code; for example, they’re pervasively used by the Linux kernel developers. However, for small, agile teams (especially in the business context), they can be overkill and pose potential problems.
In such a team, you typically have one eternal branch, from which production releases are made, and to which people merge changes from short-lived feature branches. In such a setting, it’s hard to tell how the history of a project has progressed. GitFlow, a popular way of working with Git, advocates merge commits everywhere, and people are struggling with it.
I’ll refer you to the visual argument from that last post:

Setting aside the fact that this history is littered with merge commits, the author makes a point that with this kind of an entangled graph, it’s practically impossible to find anything in it. Whether that’s true or not I’ll leave for you to decide, but there’s definitely a case for linear history there.
There’s another, oft-overlooked quirk here. Quick: look again at the second image above, the one with merge commit number 9. Can you tell, from the image alone, which commit was the tip of main before the merge happened? Surely it must be 8, because it’s on the gray line, right?
Yeah: on the image. But when you look at the merge commit itself, it’s not that obvious. Under the hood, all the commit really says is:
Merge: 8 6
So it tells you that these two parents have been merged together, but it doesn’t tell you which one used to be main. You might guess 8, because it’s the leftmost one, but you don’t know for sure. (Remember, branches in Git are just pointers to commits.) The only way (that I know of) to be sure is to use the reflog, but that is ephemeral: Git occassionally prunes old entries from reflogs.
So this prevents you from being able to confidently answer questions such as: “which features were released over the given time period?”, or “what was the state of main as of a given date?”.
That’s also why you can’t git revert a merge commit—that is, unless you tell Git which of the parent commits you want to keep and which to discard.
Squash and merge
In the merge commit-based approach, we don’t rewrite history: once a commit is made, it stays; repository only grows by accretion. In contrast, the other two approaches use Git’s facilities for rewriting history. As we’ll see, the fundamentals are the same: where they differ is commit granularity.
Coming back to our example: when squashing, we mash together the changes introduced by commits 4, 5, and 6 into a single commit (“S”), and then replay that commit on top of main.

The feature branch is still there, but I didn’t include it on this picture because it’s no longer relevant—it typically gets deleted upon merge (which, as we will see, might not actually be a good idea).
There’s a lot to like about this approach, and some teams advocate for it. The biggest and most obvious benefit is likely that the history becomes very legible. It’s linear and there’s a one-to-one correspondence between commits on main and pull requests (and, mostly, either features or bugfixes). Such a history can be of great help in project management: it becomes very easy to answer the questions which were nigh impossible to answer in the merge-commit approach.
Rebase and merge
This situation is similar to the previous one, except that we don’t squash commits 4–6 together. Instead, we directly replay them on top of main.

Let me start with a long digression. You might guess, from the GitHub screenshot at the top of this post, that I’m in this camp, and you’d be right. In fact, I used to squash and merge feature branches, but I switched to the rebase-and-merge approach after introducing probably the single biggest improvement to the quality of my work over recent years:
I started writing meaningful commit messages.
In the not-too-distant past, my commit messages used to be one-liners, as evidenced, for example, in the history of Skyscraper. These first lines haven’t changed much, but now I strive to augment them with explanation of why the change is being made. When it fixes a bug, I explain what was causing it and how the change makes the bug go away; when it implements a feature, I highlight the specifics of the implementation. I might not write more code these days, but I certainly write more prose: it’s not uncommon for me to write two or three paragraphs about a +1/−1 change.
So my commit messages now look like this (I’m taking a recent random example from the Fy! app’s repo):
app/tests: allow to mock config
Tests expected the code-push events to fire, but now that I’ve
disabled CP in dev, and the tests are built with the dev aero profile,
they’d fail.
This could have been fixed by building them with AERO_PROFILE=staging
in CI, but it doesn’t feel right: I think tests shouldn’t depend on
varying configuration. If a test requires a given bit of configuration
to be present, it’s better to configure it that way explicitly.
Hence this commit. It adds a wrap-config mock and a corresponding
:extra-config fixture, which, when present (and it is by default),
will merge the value onto generated-config.
I’m very conscious about having a clean history. I’m aiming for each commit to be small (with the threshold at approximately +20/−20 LOCs) and introduce a coherent, logical change.
That’s not to say I always develop that way, of course. If you looked at a git log of my work-in-progress branch, chances are you’d see something like this:
5d64b71 wip
392b1e0 wip
0a3ad89 more wip
3db02d3 wip
But before declaring the PR ready to review, I’ll throw this history away (by git reset --mixed $(git merge-base feature main)) and re-commit the changes, dividing them into logical units and writing the rationales, bit by bit.
The net result of rigorously applying this practice is that
you can do git annotate anywhere, and learn about why any line of code in the codebase is the way it is.
I can’t emphasize enough how huge, huge impact for the developer’s wellbeing this has. These commits messages, when I read them back weeks or months later, working on something different but related, almost read as little love letters from me-in-the-past to me-now. They reduce the all-important WTFs/minute metric to zero.

They’re also an aid in reviewing code. My PR notes usually say “please read each commit in isolation.” I’ve found it easier to follow a PR when it tries to tell a story, and each commit is a milestone down that road.
Ending the digression: can you see why I prefer rebase-and-merge over squash-and-merge? Because, all the benefits notwithstanding, squashing irrevocably loses context.
Now, instead of each line being a result of a small, +20/−20 change, you can only tell that it’s part of a set of such changes — maybe ten of them, maybe fifty. You don’t know. Sure you can go look in the original branch, but it’s an overhead, and what if it’s been deleted?
So yeah. Having those love letters all in place, each carefully placed and not glued to others, is just too much of a boon to let go. But it’s not to say that rebasing-and-merging is without downsides.
For example, it’s again hard to tell how many features were deployed over a given period of time. More troublesomely, it’s harder to revert changes: typically you want to operate on a feature level there. With squash-and-merge, it takes one git revert to revert a buggy feature. With rebase-and-merge, you need to know the range.
Worse yet: it’s more likely for a squashed-and-merged commit to be cleanly undone (or cherry-picked) than for a series of small commits. (I sometimes deliberately commit wrong or half-baked approaches that are changed in subsequent commits, just to tell the story more convincingly, and it’s possible that each of these changes individually causes trouble but that they cancel each other in squash.)
So I’m not completely happy with either of the three approaches. Which finally brings me to my preferred fourth approach, one that Git (yet?) doesn’t allow for:
Rebase, group and merge
You know the “group” facility of vector graphics programs? You draw a couple of shapes, you group them together, and then you can apply transformations to the entire group at once, operating on it as if it were an atomic thing. But when need arises, you can “ungroup” it and look deeper.
That’s because sometimes there’s a need to have a “high-level” view of things, and sometimes you need to delve deeper. Each of these needs is valid. Each is prompted by different circumstances that we all encounter.
I’d love to see that same idea applied to Git commits. In Git, a commit group might just be a named and annotated range of commits: feature-a might be the same as 5d64b71..3db02d3. Every Git command that currently accepts commit ranges could accept group names. I envision groups to have descriptions, so that git log, git blame, etc could take --grouped or --ungrouped options and act appropriately.
Obviously, details would need to be fleshed out (can groups overlap? can groups be part of other groups?), and I’m not that familiar with Git innards to say with confidence that it’s doable. But the more I think about it, the more sound the idea seems to me.
I think creating a group when doing a rebase-and-merge could bring together the best of all three worlds, so that we can have all our cakes and eat them too.
2 It’s Dog Day here in Poland as I write these words. Happy Dog Day!